IME mode and CJK languages
The component supports general IME mode that maps raw input sequence to dictionary entries. The keyboard collects clicked characters in a staging area and shows the matching entries as suggestions. Users can either click a suggestion button to send its content as input, or click the space key to send the first suggestion.
To enable IME mode, call the LoadImeTable method, specifying the language for which to load IME table and the dictionary file path. The table file format contains one line per entry, with three tab delimited values: raw input, translation, frequency. For example, a hypothetical IME table that translates chemical formulas to compound's common name could look like this:
C#
 Copy Code Copy Code
|
|---|
| c3h8o Propan-2-ol 2 c3h8o Propanol 4 h2o Water 1 c3h8o Methoxyethane 1 c3h8o Propan-1-ol 3 c2h6 Ethane 1 c3h7br 1-bromopropane 3 c3h7br 2-bromopropane 2 .... vk.LoadImeTable( new CultureInfo("en-US"), "chemical.txt"); |
and suggestions for the partial input "c3h" will look like this:

The component can parse IME tables from the Linux Ibus project to implement various Chinese transliteration systems. For example you can load following tables for respectively mainland China's simplified Chinese, Taiwan's traditional Chinese and Hong-Kong's Cangjie input methods:
Zhuyin
https://github.com/definite/ibus-table-chinese/blob/master/tables/zhuyin.txt
Cangjie
https://github.com/definite/ibus-table-chinese/blob/master/tables/cangjie/cangjie3.txt
The following image shows the Zhuyin input method:
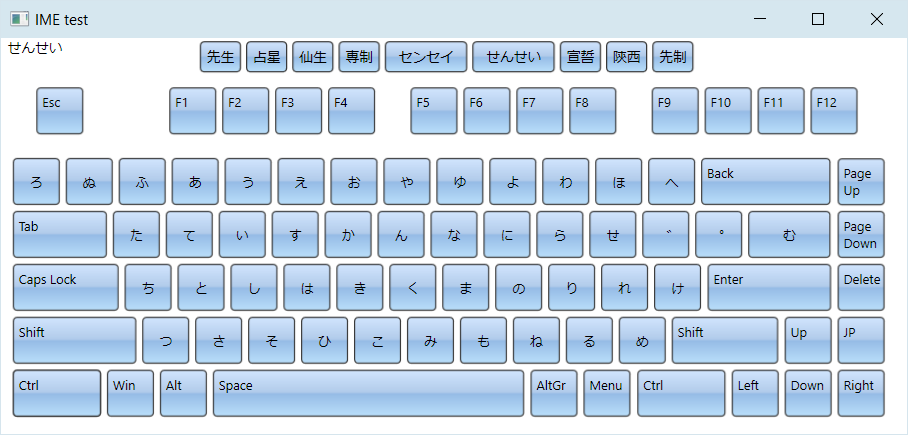
If current language is Japanese, the keyboard renders Hiragana characters. In addition, LoadImeTable can parse tables from Google's mozc project to convert Hiragana to Kanji. To enable this mode, specify path to a directory containing the 10 dictionary files from following link:
https://github.com/google/mozc/tree/master/src/data/dictionary_oss
This image demonstrates Hiragana to Kanji conversion: